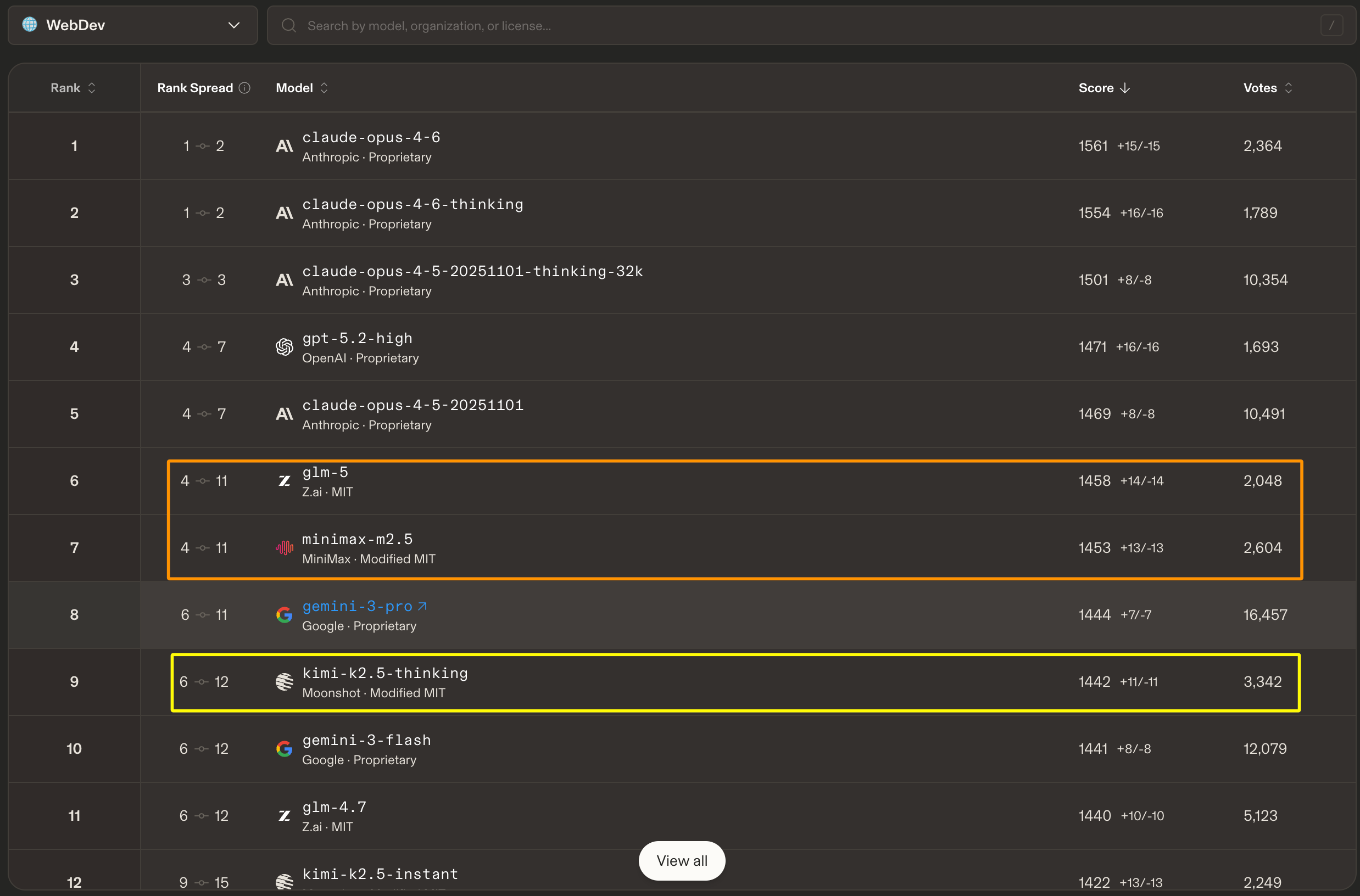
之前一个月使用了 MinMax-M2.1,GLM-4.7 和 Kimi-2.5 ,最终给我体验最好的是发布最晚的 Kimi-2.5。到了 2 月份, MinMax-M2.5,GLM-5 轮番上阵,排名很快就变化了。虽然总分数没啥差别,但对于我们个人或是中小型公司来说,卷起来是好事。
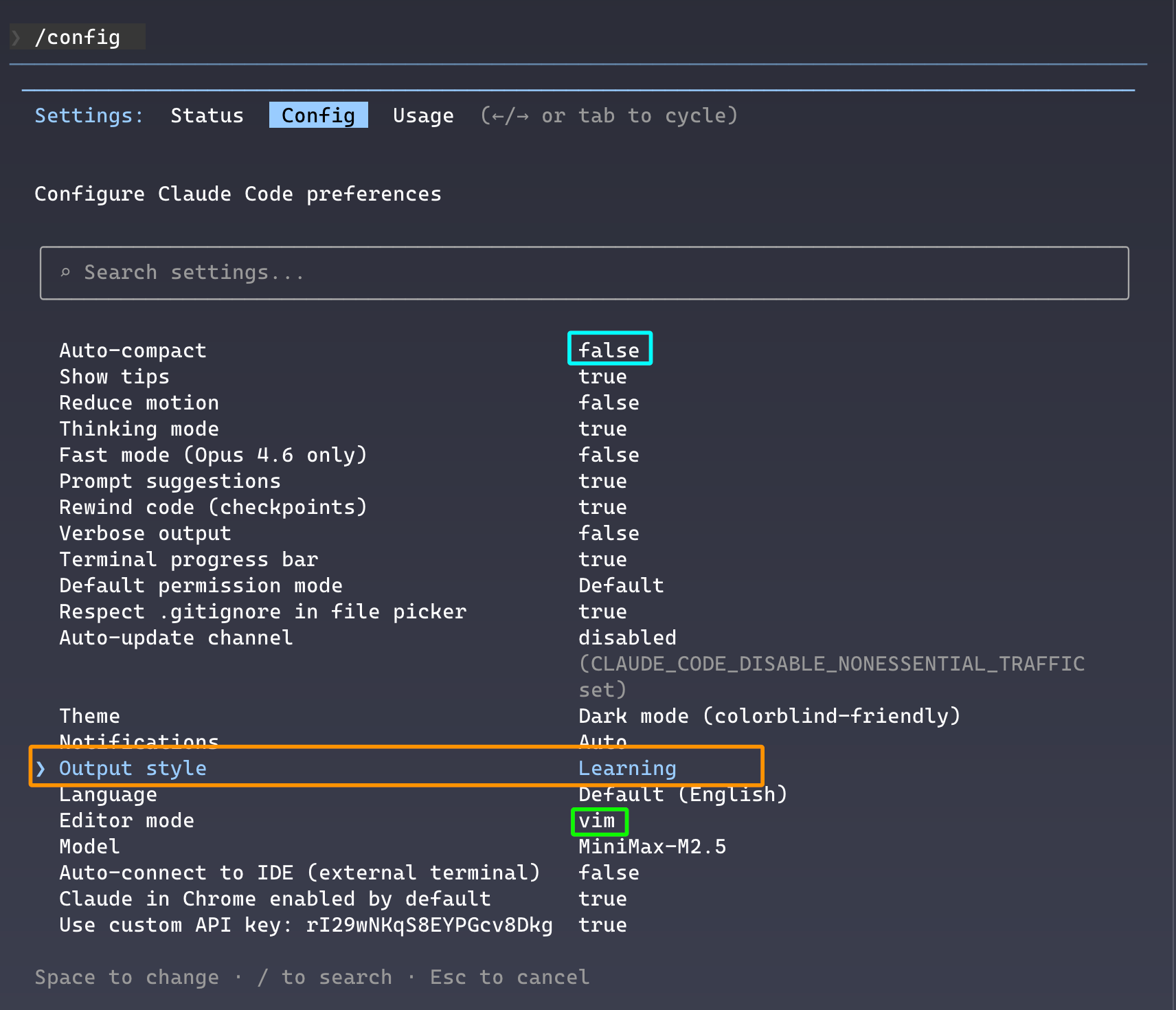
我们经常说没时间学习,可有那么一丢丢时间时,人们往往又不想学习。时间真的像双手捧起的水,从缝隙间缓缓流走,怎么都留不住。去年虽然写了一些 Python 代码,但大部分代码都是 AI 写的,所以就想借着 CC 快速了解一下它的基本语法(基于《Python 编程(第3版)》)。首先,我开了学习模式,好像也没看出啥区别😂:
然后,为了防止 LLM 不阅读原教材,而是自己基于已有知识搜索或总结,我开了 3 个 CC,分别连上 MinMax-M2.5,GLM-5 和 Kimi-2.5。到时,谁忽悠我,我就知道了。对比下来,都读了原教材,但总结的内容,MinMax 有点过于简洁,下面是总结的正文。
变量和简单的数据类型
变量
message = "Hello Python!" # 定义 message 变量
print(message)
message = 123
print(message)
var_flag = True
varFlag = true # 可以,但不推荐
变量是可以被赋值的标签,它指向特定的值,且可以随时指向新的值。
- 变量无需声明类型
- 变量名只能包含字母、数字和下划线,且只能以字母或下划线作为开头。
- 变量名不能包含空格,但能使用下划线来分隔其中的单词。
- 变量名应既简短又具有描述性。
- 一般都用小写的变量名,全大写的变量名一般用于常量,大驼峰命名法则用于类的定义(与 Java 一致)。
- 变量可以重复赋值,甚至可以改变类型
- Java 中默认驼峰命名,但在 Python 中默认是蛇形命名法
字符串
- 单引号
''和双引号""都可以用来标识字符串 - 如果字符串中有单引号,那就用双引号,反之亦然
- 丰富的内置方法:
title(),upper(),lower(),strip()等 - f-string 是推荐的字符串格式化方式(Python 3.6+)
a='an"d3"11' # 单引号中包含双引号
print(a)
ab = "Hello'Time" # 双引号中包含单引号
print(ab)
name = 'Hey, demon.lee'
print(name.title()) # Hey, Demon.Lee 首字母大写
print(name.upper()) # HEY, DEMON.LEE 全大写
print(name.lower()) # hey, demon.lee 全小写
s = " hi,python 123 "
print(f"[{s.lstrip()}]") # [hi,python 123 ] 去掉左边空格
print(f"[{s.rstrip()}]") # [ hi,python 123] 去掉右边空格
print(f"[{s.strip()}]") # [hi,python 123] 去掉两边空格
url="www.google.com/hey/123"
print(url.removeprefix("www.")) # 删除前缀:google.com/hey/123
print(url.removesuffix("www.")) # 删除后缀(没匹配到):www.google.com/hey/123
print(url.removesuffix("/123")) # 删除后缀:www.google.com/hey
msg = "\tHow are you?"
greet = f"{name.title()} {msg}" # 使用 f-string 进行字符串格式化
print(greet) # Hey, Demon.Lee How are you?
数字
1、主要是整数和浮点数
2、任意两个数相除,结果总是浮点数
c = 10/5
print(c) # 2.0
print(type(c)) # <class 'float'>
3、只要有操作数是浮点数,结果就是浮点数
c = 1 +2.2
print(c) # 3.2
4、浮点数计算,末尾的小数位可能出现不稳定的误差
c = 0.1 + 0.2
print(c) # 0.30000000000000004
print(f"{c:.1f}") # 0.3 字符串格式化,保留1位小数
print(f"{c:.2f}") # 0.30 字符串格式化,保留2位小数
5、长整数表达可以使用下划线(Python 3.6+)
aa = 12_000_000_000
print(aa) # 12000000000
6、同时给多个变量赋值
aa,bb,cc = 11,22,"33"
print(aa,bb,cc) # 11 22 33
print(type(cc)) # <class 'str'>
7、乘方运算 ** ,整除运算 //
a = 2 ** 3
b = a / 5
c = a // 6
print(a,b,c) # 8 1.6 1
8、转字符串,可以使用 str() 方法
a = 22
b = 33.21
print("a: "+str(a)) # a: 22
print("b: "+str(b)) # b: 33.21
注释
单行注释,行内注释
# 这是单行注释
print("Hello!") # 行内注释
列表
列表简介
1、使用 [] 定义,元素用 , 分隔,支持存储任意类型
2、有序,可修改,动态数组,自动扩容
3、支持负索引,比如 -1 表示最后一个元素,-2 表示倒数第二个元素
arr = ['字符串', 123, 33.23, True, "test"]
print(arr) # ['字符串', 123, 33.23, True, 'test']
print(arr[1], arr[-1]) # 123 test
4、修改元素
arr[0] = "字符"
print(arr) # ['字符', 123, 33.23, True, 'test']
5、添加元素:append 在末尾追加,insert 在指定位置插入
arr = [] # 创建空列表
arr.append("你好") # 追加元素
arr.append(123)
print(arr) # ['你好', 123]
arr.insert(1, True) # 在 index = 1 的位置插入数据,后面的数据自动往后移动
print(arr) # ['你好', True, 123]
6、删除元素:del ,pop ,remove
arr = ['字符串', 123, 33.23, True, "test"]
del arr[0] # 按索引删除
print(arr) # [123, 33.23, True, 'test']
e = arr.pop() # 弹出最后一个元素
print(e) # test
print(arr) # [123, 33.23, True]
e = arr.pop(1) # 按指定位置弹出元素
print(e) # 33.23
print(arr) # [123, True]
arr.append(123)
arr.remove(123) # 按值删除,但只匹配第一个,无返回值
print(arr) # [True, 123]
7、排序:sort 原地永久排序,sorted 临时排序,reverse 反转列表,len 计算列表长度
arr = [121, 33, 1, 99, 68, 12, 77]
arr1 = sorted(arr) # 临时排序
print(arr1) # [1, 12, 33, 68, 77, 99, 121]
print(arr) # [121, 33, 1, 99, 68, 12, 77]
print(len(arr)) # 7
arr.reverse() # 反转,永久
print(arr) # [77, 12, 68, 99, 1, 33, 121]
arr.sort() # 永久排序(默认升序)
print(arr) # [1, 12, 33, 68, 77, 99, 121]
arr.sort(reverse=True)
print(arr) # [121, 99, 77, 68, 33, 12, 1]
操作列表
1、代码块通过缩进界定,不像 Java 或 C 中的 {} ,Python 中 4 个空格表示缩进,注意不要混用 Tab 和空格
2、遍历列表:for item in list:
arr = [121, 33, 1]
for i in arr:
print(i) # 注意缩进
print(f"arr len: {len(arr)}") # 非循环体不需要缩进
# 输出内容如下:
121
33
1
arr len: 3
如果是空循环体,可以用 pass 代替。
3、创建数值列表:range 函数
# range(stop) - 从 0 开始,stop 不包含在内
# range(start, stop) - stop 不包含在内
# range(start, stop, step) - 带步长
for value in range(1, 3):
print(value)
# 输出内容如下:
1
2
for value in range(2):
print(value)
# 输出内容如下:
0
1
arr = list(range(1, 10, 3)) # 转列表
print(arr) # [1, 4, 7]
4、列表统计:min ,max,sum
arr = [1,3,5]
print(min(arr)) # 1
print(max(arr)) # 5
print(sum(arr)) # 9
5、列表推导
even_squares = [x ** 2 for x in range(2,11,2)]
print(even_squares) # [4, 16, 36, 64, 100]
6、切片:Python 切片 list[0:3] 类似 Java 的 list.subList(0, 3)
- 创建原列表的副本,不影响原列表
list[start:end]包含 start,不包含 stoplist[:]相当于复制整个列表,但仍属于浅拷贝
arr = ['Hey','你好','时间']
arr1 = arr[0:1]
print(arr1) # ['Hey']
arr1.append('world')
print(arr) # ['Hey', '你好', '时间']
print(arr1) # ['Hey', 'world']
print(arr[:2]) # ['Hey', '你好'] 复制:从 0 到 1
print(arr[2:]) # ['时间'] 复制:从 2 到末尾
print(arr[-2:]) # ['你好', '时间'] 复制:从倒数第 2 到末尾
7、元组(Tuple):不可变列表,用于存储不可变数据,不能修改元素值,但可以给变量重新赋值,用 () 定义
arr1 = (1, 3, 9)
arr2 = (1) # 这不是元组,而是数字 1
print(type(arr2)) # <class 'int'>
arr3 = (1,) # 这是单元素元组
print(type(arr3)) # <class 'tuple'>
arr1[0] = 0 # 提示错误:TypeError: 'tuple' object does not support item assignment
arr1 = ('hi', '2026')
print(arr1) # ('hi', '2026')
8、代码风格(PEP 8)
- 一行不超过 80 个字符
- 函数之间空两行
- 类之间空两行
- 逻辑块之间空一行
- 行内注释与代码间隔2个空格
- 长行可以使用
()实现换行 - 比较运算符两边各加一个空格
if 语句
1、Python 中没有 switch...case (挺好,代码的坏味道,Java 中我也不会用这个语法),基本结构如下:
if xx1:
xxx
elif xx2:
xxx
else:
xxx
age = 12
if age <= 6:
price = 0
elif age < 18:
price = 15
else:
price = 30
print(f"Your admission cost is ${price}.") # Your admission cost is $15.
2、用 == ,!= 比较值,用 and,or,not 等进行逻辑运算,对应 Java 中的 &&,|| 和 !
3、in 和 not in 可以用来检查列表成员是否存在,当然,也能用在字符串,字典等类型中
a = 12
b = 13
c = 'hello'
d = "hello"
print(a==b) # False
print(c==d) # True,没错,字符串也是用 == 比较
f = a == b
if not f:
print("hey...")
arr = ["Jack", "小马", "2026"]
if arr: # 检查列表是否为空
print("arr is not empty.")
if '2026' in arr:
print("here is 2026...")
4、支持链式比较,比如:11 < x < 50
5、三元表达:status = 'adult' if age >= 18 else 'minor'
字典
1、键值对,key 唯一,用 {} 表示,定义时,用 : 分隔元素的 key 和 value
d1 = {} # 定义空字典
d2 = {'k1': 11, 2: 'test'}
2、基本操作
- 获取元素值:
dict[key],dict.get(key),前者对于不存在的 key 会报错,后者则返回 None - 遍历 key 列表,value 列表 和 key-value 列表分别是:
dict.keys(),dict.values()和dict.items()
print(d2['k1']) # 11
print(d2[2]) # test
print(d2['k2']) # 元素不存在,提示错误:KeyError: 'k2'
print(d2.get('k2')) # 元素不存在,不报错,返回 None
print(d2.get('k2', 'hey')) # 元素不存在,返回默认值 hey
d2['k2'] = 'Hi' # 增加或修改元素
d2.update(k1=110, user="root") # 增加或修改元素
del d2['k2'] # 删除指定 key 的元素
d2.pop('user', None) # 移除指定 key 的元素,如果 key 不存在,就返回 None
print(d2.keys()) # dict_keys(['k1', 2])
print(d2.values()) # dict_values([11, 'test'])
print(d2.items()) # dict_items([('k1', 11), (2, 'test')])
for k, v in d2.items():
print(k, v)
3、集合:set,无序不重复的元素集合
set1 = set() # 定义空集合
set2 = set(d2.values()) # 使用 d2 的值集合进行初始化
set3 = {'k1', 11, True}
set3.add('Hey')
set3.remove(True)
print(set2) # {'test', 11}
print(set3) # {'k1', 'Hey', 11}
print('c' in set3) # False
4、嵌套:字典列表,字典中存储字典,字典中存储列表
# 字典列表
alien_0 = {'color': 'green', 'points': 5}
alien_1 = {'color': 'yellow', 'points': 10}
alien_2 = {'color': 'red', 'points': 15}
aliens = [alien_0, alien_1, alien_2]
print(aliens) # [{'color': 'green', 'points': 5}, {'color': 'yellow', 'points': 10}, {'color': 'red', 'points': 15}]
# 字典中存储字典
users = {
'aeinstein': {
'first': 'albert',
'last': 'einstein',
'location': 'princeton',
},
'mcurie': {
'first': 'marie',
'last': 'curie',
'location': 'paris',
},
}
# 字典中存储列表
pizza = {
'crust': 'thick', # 值是字符串
'toppings': ['mushrooms', 'extra cheese'], # 值是列表
}
用户输入和 while 循环
input 函数
- 程序暂停下来,等待用户输入
- 返回值类型是字符串,如果需要整数或浮点数,需要进行转换
msg = input("hello, how old are you?")
age = int(msg)
print(age)
while 循环
- 基础语法跟 Java 中没大区别
- 可以配合用来移动或删除列表中的元素
- while-else 特色结构:else 在循环正常结束时执行,如果用 break 退出,else 不会执行
# 删除列表中的元素
pets = ['dog', 'cat', 'dog', 'goldfish', 'cat', 'rabbit', 'cat']
while 'cat' in pets:
pets.remove("cat")
print(pets) # ['dog', 'dog', 'goldfish', 'rabbit']
# while 判断集合时会自动判断是否为空,不需要额外的 empty 判断
while xxList: # 如果 xxList 为空,那么判断就是 False
pass
# while-else 特色结构
numbers = [1, 3, 5, 7, 9]
target = 4
index = 0
while index < len(numbers):
if numbers[index] == target:
print(f"找到 {target} 在索引 {index}")
break
index += 1
else:
print(f"未找到 {target}")
函数
Python 中函数是一等公民,可以赋值给变量、作为参数传递等。
1、定义
- 使用 def 关键字
- 不需要返回类型声明,可以返回任意类型
- 使用
""" """文档字符串标识函数说明
# 定义
def greet_user(name):
"""显示简单的问候语""" # 函数注释
print(f"Hello, {name}")
return f"hey,{name}"
# 调用
greet_user("Pony") # Hello, Pony
2、参数传递:默认值,按位置传参,按关键字传参
- 默认值参数必须放在参数列表末尾
- 按关键字传参,顺序不重要
- 位置传参与关键字传参混合使用时,位置实参必须在关键字实参前面
# 默认值
def describe_pet(pet_name, animal_type='dog'): # animal_type 默认 'dog'
print(f"I have a {animal_type} named {pet_name}.")
describe_pet('willie') # 按位置传参
describe_pet(animal_type='hamster', pet_name='harry') # 按关键字传参,顺序不重要
3、任意数量参数
*args:任意数量位置参数,元组类型**kargs:任意数量关键字参数,字典类型*args和 **kwargs各自最多只有一个,且 **kwargs必须在最后
def make_pizza(*toppings):
print(toppings)
make_pizza('pepperoni', 'mushrooms', 'cheese') # ('pepperoni', 'mushrooms', 'cheese')
def build_profile(first, last, **user_info):
user_info['first_name'] = first
user_info['last_name'] = last
return user_info
user = build_profile('albert', 'einstein', location='princeton', field='physics')
print(user) # {'location': 'princeton', 'field': 'physics', 'first_name': 'albert', 'last_name': 'einstein'}
4、模块导入
# 导入整个模块
import pizza
# 导入特定函数
from pizza import make_pizza
# 给导入的模块设置别名
import pizza as p
# 给导入的函数设置别名
from pizza import make_pizza as mp
# 不推荐:导入模块中的所有函数
from pizza import *
类
1、定义类与创建实例
- 类似于 Java,也是使用 class 声明类
- 构造方法:
__init__,类似于 Java 的构造函数 self类似于 Java 类中的this关键字,但必须显示声明- 创建实例直接调用类名,不需要 Java 中的
new关键字 - 访问属性: instance.attribute(惯用直接访问),调用方法: instance.method()
- 可以动态添加/修改属性
class Dog:
"""小狗的简单模拟"""
def __init__(self, name, age):
"""初始化属性"""
self.name = name
self.age = age
self.description = '' # 给属性设置默认值
def sit(self):
"""蹲下"""
print(f"{self.name} is now sitting.")
def roll_over(self):
"""打滚"""
print(f"{self.name} rolled over!")
def mock(self, mock_flag):
"""mock"""
self.mock_flag = mock_flag # 动态添加成员属性
print(f"{self.name} mock: {mock_flag}")
dog1 = Dog("Jim", 3)
print(dog1) # <__main__.Dog object at 0x1077052b0>
print(dog1.name) # Jim
dog1.roll_over() # Jim rolled over!
2、继承
- 单继承: Child(Parent),也支持多继承: Child(Parent1, Parent2, Parent3)
- 调用父类构造函数:
super().__init__ - 重写方法直接定义同名方法即可
- 当然,组合优于继承
class Car:
def __init__(self, make, model, year):
self.make = make
self.model = model
self.year = year
self.odometer_reading = 0
def get_descriptive_name(self):
return f"{self.year} {self.make} {self.model}"
class ElectricCar(Car): # 继承 Car
def __init__(self, make, model, year):
super().__init__(make, model, year) # 调用父类构造
self.battery_size = 75
def describe_battery(self):
print(f"This car has a {self.battery_size}-kWh battery.")
my_tesla = ElectricCar('tesla', 'model s', 2019)
print(my_tesla.get_descriptive_name()) # 2019 tesla model s
my_tesla.describe_battery() # This car has a 75-kWh battery.
3、访问控制
- 没有真正的私有属性,靠约定
_var约定私有,__var名称修饰@property类似 Java 中的 getter()__方法名__(前后各两个下划线)被称为魔术方法或特殊方法,它是Python 保留的,在特定时机被自动调用
class Person:
def __init__(self, name, age):
# 1. 公开属性 - 任何地方都可以访问
self.name = name
# 2. 约定私有 - 单下划线开头
self._age = age
# 3. 名称修饰私有 - 双下划线开头
self.__secret = "hidden"
# getter
@property
def age(self):
return self._age
# setter
@age.setter
def age(self, value):
self._age = value
# 公开方法
def say_hello(self):
print(f"Hello, I'm {self.name}")
# 约定私有方法
def _internal_method(self):
print("Internal use only")
# 名称修饰私有方法
def __private_method(self):
print("Private by name mangling")
jack = Person('Jack', 33)
print(jack.name) # jack
print(jack._age) # 33 可以访问,但不建议
jack.age = 28 # 通过 `@age.setter` 实现 setter 效果
print(jack.age) # 28 通过 `@property` 实现 getter 效果
print(jack.__secret) # AttributeError: 'Person' object has no attribute '__secret'
print(jack._Person__secret) # hidden 名称修饰后可访问
文件和异常
文件
1、读取
- 使用
with关键字自动管理文件资源,不需要手动调用close()(Java 需要 try-finally 或 try-with-resources) - 大文件,推荐按行读取
# 方式1:一次性加载
with open('pi_digits.txt') as file_object:
contents = file_object.read()
print(contents)
# 方式2:逐行迭代,如果是大文件,推荐此方式
with open('langchain_agent_shell.py') as file_object:
for line in file_object:
print(line.rstrip())
# 方式3:一行行读取
with open('langchain_agent_shell.py') as file_object:
line1 = file_object.readline()
line2 = file_object.readline()
print(line1)
print(line2)
# 方式4:一次性加载所有行到列表
with open('langchain_agent_shell.py') as file_object:
lines = file_object.readlines()
print(f"line num: {len(lines)}")
for line in lines:
print(line.rstrip())
2、写入
模式:r 读取(默认),w 写(覆盖),a 追加,
with open("demo-py.txt", "w") as f:
f.write("你好,Python......\n人生苦短,我用Python。\n")
with open("demo-py.txt", "a", encoding='utf-8') as f:
f.write("测试123......")
3、JSON 数据处理
- 将 Python 对象转成字符串:
json.dumps() - 将字符串转 Python 对象:
json.loads()
>>> jstr = '{"你好":"hello", "u2":"测试", "u3": null}'
>>> d1 = json.loads(jstr)
>>> type(d1)
<class 'dict'>
>>>
>>> print(d1)
{'你好': 'hello', 'u2': '测试', 'u3': None}
>>>
异常
1、try-except-else-finally 结构,else 在无异常时执行
try:
file = open('data.txt')
data = file.read()
except FileNotFoundError:
print("File not found")
else:
print("File found")
finally:
print("Cleanup code here")
# 如果 data.txt 不存在,则输出
File not found
Cleanup code here
# 如果 data.txt 存在,则输出
File found
Cleanup code here
2、常见异常
ZeroDivisionError # 除零
FileNotFoundError # 文件不存在
ValueError # 值错误(如 int("abc"))
TypeError # 类型错误
IndexError # 索引越界
KeyError # 字典键不存在
AttributeError # 属性不存在
NameError # 变量未定义
SyntaxError # 语法错误
ModuleNotFoundError # 模块不存在
ImportError # 导入错误